
합성(가짜) 데이터로 훈련된 AI모델들이 온다 | 매거진에 참여하세요
합성(가짜) 데이터로 훈련된 AI모델들이 온다
#합성 #시뮬레이션 #가상 #AI #데이터 #훈련




가짜 데이터가 진짜 시장을 먹는다. 진짜보다 더 중요한 ‘가짜 데이터’
2025년, 데이터는 여전히 인공지능 산업의 원유이지만, 실제(real) 데이터만으로는 한계에 도달했습니다.
개인정보 보호 규제, 데이터 수집 비용, 그리고 데이터 편향 문제 때문에 기업들은 점점 더 합성 데이터(Synthetic Data)에 의존하고 있습니다.
합성 데이터란 실제 데이터를 수집하지 않고, AI나 시뮬레이션을 통해 인공적으로 생성한 데이터를 뜻합니다.
사진, 영상, 텍스트, 센서 데이터까지 모두 가짜지만, 학습과 테스트에는 오히려 더 유용할 수 있습니다.
가짜 데이터는 더 이상 ‘보조 수단’이 아닙니다.
자율주행, 의료, 로보틱스 같은 산업에서는 합성 데이터가 시장을 먹어치우는 수준으로 주류가 되어가고 있습니다.
왜 합성 데이터가 필요한가?
합성 데이터가 각광받는 이유는 단순합니다. 실제 데이터를 쓰기 어려워졌기 때문입니다.
- 프라이버시 규제: GDPR, CCPA 같은 규제로 인해 실제 고객 데이터를 수집하고 공유하는 것은 점점 더 어려워졌습니다.
- 수집 비용: 자율주행차의 사고 데이터를 모으려면 수천만 km를 달려야 하지만, 합성 시뮬레이션이라면 클릭 몇 번으로 가능해집니다.
- 데이터 희소성: 희귀질환 환자의 의료 데이터, 드물게 발생하는 공장 사고 데이터처럼 현실에서 얻기 힘든 사례를 합성 데이터로 대체할 수 있습니다.
- 편향 교정: 실제 데이터에는 사회적 편향(성별, 인종 등)이 들어 있지만, 합성 데이터는 이를 조절해 균형 잡힌 학습셋을 만들 수 있습니다.
결국 합성 데이터는 “데이터 민주화”를 가능하게 하는 열쇠로 주목받고 있습니다.

합성 데이터가 바꾸는 산업들
1) 자율주행
Waymo, Tesla, 현대차까지 모든 자율주행 기업은 실제 도로 주행 외에도 가상 환경 시뮬레이션을 사용합니다.
예:
비 오는 날 고속도로 주행
갑자기 뛰어드는 보행자
신호등 고장 상황
이런 극단적이고 위험한 상황은 실제로 재현하기 어렵지만, 합성 데이터로 무한히 학습할 수 있습니다.
2) 의료
합성 의료 데이터는 환자 개인정보를 침해하지 않으면서도 AI 모델을 훈련할 수 있게 합니다.
GE Healthcare는 합성 MRI 이미지를 활용해 희귀질환 진단 모델을 훈련
NVIDIA Clara는 합성 의료 이미지 라이브러리를 구축해 글로벌 병원들과 공유
이는 “데이터 공유 없는 협력”이라는 새로운 패러다임을 만들어냈습니다.
3) 로보틱스
로봇 팔, 드론, 물류 로봇은 현실 세계에서 수백만 번의 시도를 반복할 수 없습니다.
하지만 합성 시뮬레이션 안에서는 하루 만에 수십억 번의 시행착오를 겪을 수 있습니다.
OpenAI의 로봇 손 훈련은 실제보다 합성 데이터 환경에서 훨씬 더 빠르게 학습되었습니다.
합성 데이터 시장의 성장
2025년 글로벌 합성 데이터 시장 규모는 약 30억 달러로 추산되며, 2030년에는 200억 달러 이상으로 성장할 것으로 예상됩니다.
주요 플레이어: Mostly AI, Synthesis AI, Gretel.ai, NVIDIA Omniverse
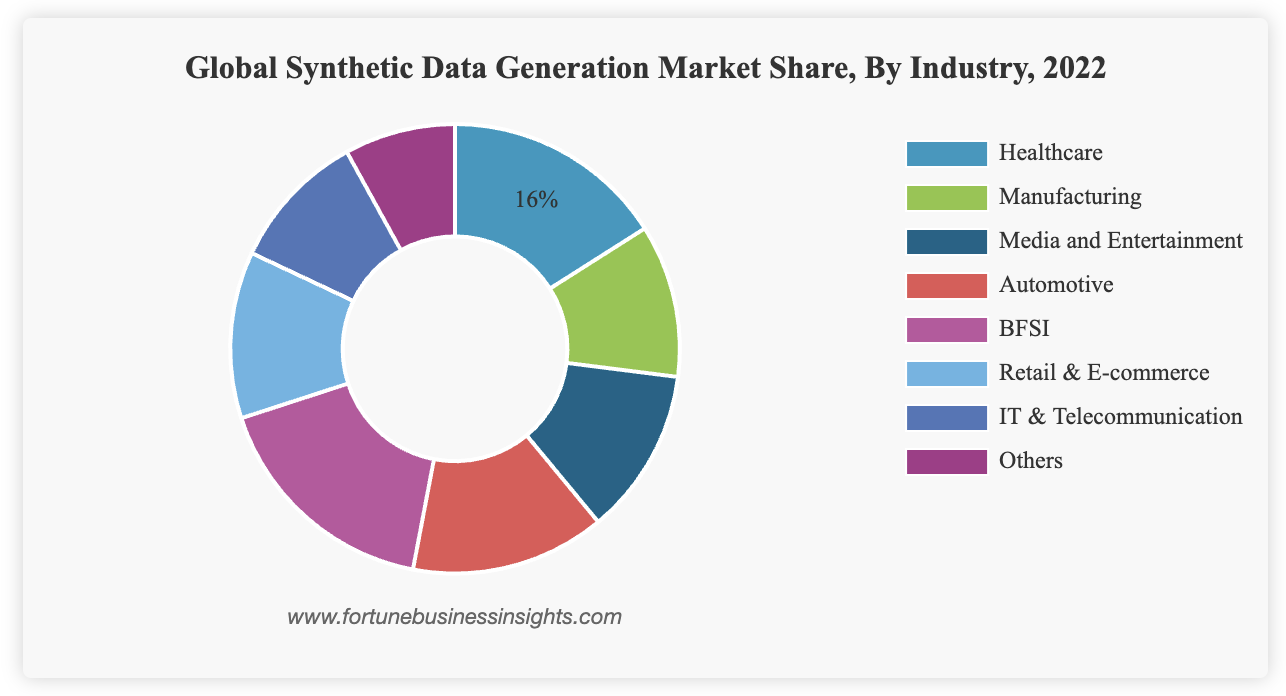
투자 동향: VC들이 합성 데이터 스타트업에 적극적으로 투자하고 있으며, 실제 데이터보다 ROI가 높다는 평가를 받고 있습니다.
합성 데이터는 단순히 기술적 대안이 아니라, 데이터 자체를 하나의 상품으로 만드는 경제를 형성하고 있습니다.
기업들은 이제 “실제 데이터 구매”보다 “합성 데이터 구독”을 선택하기 시작했습니다.
1. Mostly AI
본사: 오스트리아 비엔나
특징: 합성 데이터 분야의 초기 선도 기업 중 하나.
기술: ‘AI 기반 개인정보 합성’에 강점이 있으며, 실제 고객 데이터를 통계적으로 유사하지만 개인정보가 완전히 제거된 형태로 재생성합니다.
활용 분야: 은행·보험사 같은 금융권에서 고객 데이터 보호 규제를 충족하면서도 고객 행동 분석, 신용 점수 모델링 등에 활용.
차별화 포인트: GDPR 등 유럽 규제 환경에 최적화된 솔루션 제공. “Privacy-safe AI”라는 브랜드를 강하게 내세움.
2. Synthesis AI
본사: 미국 샌프란시스코
특징: 컴퓨터 비전용 합성 데이터 생성에 특화.
기술: 3D 시뮬레이션과 생성형 AI를 결합해 인물 얼굴, 동작, 환경 데이터를 만들어냄.
활용 분야: 자율주행차의 보행자 인식, 스마트폰 얼굴 인식(Face ID), AR/VR 애플리케이션.
대표 사례: 합성 얼굴 데이터셋을 통해 편향을 줄이고, 다양한 인종·연령대의 얼굴 인식을 가능하게 함.
차별화 포인트: ‘Vision AI의 데이터 공장’이라는 컨셉. 실제 카메라 수천 대를 설치하지 않아도 수억 건의 학습 이미지를 만들어낼 수 있음.
3. Gretel.ai
본사: 미국 샌디에이고
특징: 합성 데이터 API 플랫폼. 개발자가 간단히 API 호출만으로 합성 데이터를 생성할 수 있도록 제공.
기술: 텍스트, 표 형식 데이터(tabular data), 로그 데이터까지 지원하며, 자연어 처리(NLP)와 통계적 합성 기법을 혼합.
활용 분야: 고객 행동 로그, 헬스케어 데이터, 전자상거래 데이터 등에서 프라이버시 친화적인 합성 데이터 생성.
대표 전략: “데이터를 코드처럼 다루자(Data as Code)”라는 철학으로, 합성 데이터 파이프라인을 DevOps처럼 자동화할 수 있도록 함.
차별화 포인트: 누구나 쉽게 쓸 수 있는 SaaS형 API 서비스. 스타트업부터 대기업까지 접근성이 높음.
4. NVIDIA Omniverse
본사: 미국 캘리포니아
특징: 합성 데이터 그 자체보다는 ‘디지털 트윈 & 시뮬레이션 플랫폼’ 역할.
기술: 물리 기반 렌더링(PBR)과 실제와 유사한 시뮬레이션 환경을 제공, 로보틱스·자율주행·제조 AI가 현실과 거의 같은 데이터를 학습할 수 있도록 지원.
활용 분야:
자율주행: Omniverse Replicator를 통한 대규모 가상 주행 데이터 생성
로보틱스: 물류창고·공장 환경을 디지털 트윈으로 복제, 로봇이 가상에서 학습 후 현실 투입
대표 사례: BMW가 스마트 팩토리 시뮬레이션에 Omniverse를 사용, 실제 공장 설비 도입 전에 수천 번의 합성 실험 진행
차별화 포인트: “데이터+환경”을 통째로 시뮬레이션할 수 있는 점. 합성 데이터와 디지털 트윈을 동시에 제공하는 독보적 플랫폼.
남은 한계와 논쟁
물론 합성 데이터에도 논쟁은 존재합니다.
- 현실성 부족: 아무리 정교해도 실제 세상과의 간극은 존재
- 편향의 전이: 잘못 설계된 합성 데이터는 오히려 기존 편향을 증폭할 수 있음
- 책임 소재: 합성 데이터 기반 모델이 잘못된 판단을 했을 때, 데이터 생성자와 사용자 중 누가 책임을 져야 하는가?
따라서 앞으로는 합성 데이터의 품질 평가 표준화가 핵심 이슈가 될 것입니다. ISO와 IEEE는 이미 합성 데이터 검증 프레임워크 논의를 시작했습니다.
결론: 합성 데이터가 만든 ‘가짜의 진실’
합성 데이터는 더 이상 ‘가짜’라는 말로 폄하할 수 없는 단계에 이르렀습니다.
- 현실에서는 모으기 힘든 데이터
- 개인정보 때문에 쓸 수 없는 데이터
- 위험하거나 불가능한 상황의 데이터
이 모든 것을 대신하면서, 합성 데이터는 오히려 AI 발전의 필수 자원이 되고 있습니다.
앞으로 “진짜 데이터”와 “가짜 데이터”의 경계는 흐려지고, 중요한 것은 얼마나 잘 만든 데이터인가가 될 것입니다.
합성 데이터 경제(Synthetic Data Economy)는 이미 시작되었고, 가까운 미래에 “데이터의 새로운 표준”으로 자리 잡을 것입니다.

- link_kakaolink_kakao_url
- link_operatorlink_operator_url
- link_investhelp@letspl.me
- link_ad_urllink_ad
